OpenMP
Якщо в програмі є деякий порівняно великий блок, що потребує паралельного виконання, зручно спочатку просто позначити цей блок:
#pragma omp parallel default(shared) private(i) { }
Цикл for
#pragma omp for for (i=0; i<12; i++) {}
Розмір порції
Розділення завдання на порції для кожного потоку залежить від реалізації. Часто все завдання просто ділиться на стільки послідовних частин, скільки потоків, і кожний потік виконує свою порцію.

Це зручно, якщо обробка кожної порції потребує приблизно однакового часу, але якщо кожна наступна ітерація циклу виконується довше попередньої (наприклад, коли для кожного значення i потрібно обробити дані від 0 до i), складається така ситуація, коли перший потік вже закінчив свою роботу, а останній ще довго працюватиме. Це значно знижує продуктивність.

Тому буває корисно встановити невеликий розмір однієї порції вручну таким чином, щоб кожному потоку дісталася приблизно рівноцінна частка навантаження
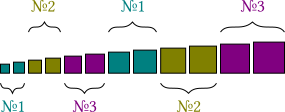
#pragma omp for schedule(static,2) for (i=0; i<12; i++) {}
Зведення
Якщо деяка величина накопичується протягом усього циклу, а після виконання усіх паралельних потоків її необхідно “зібрати” з усіх потоків, для цього використовується зведення змінної (reduction):
#pragma omp for reduction(+:summa) for (i=0; i<12; i++) { summa += i; }
В цьому прикладі після виконання усіх потоків змінну summa буде просто підсумовано, і результат збережено у змінній summa головного потоку.
Компіляція
gcc -fopenmp -o program.bin program.c
#pragma omp critical
